Seq2Seq 이론 파헤치기!!!
Seq2Seq?
2-1. Seq2Seq 이란?
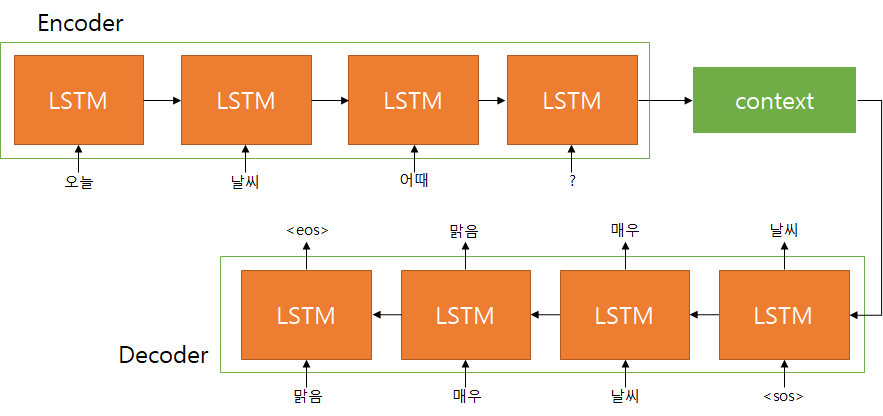
위 그림은 Seq2Seq의 기본 구조이다. Seq2Seq란 Sequence to Sequence의 약자로 문장이 형태소 분석되어 입력되면 sequence 형태로 시간 연속성을 가지는 형태소 순서의 데이터로 입력된다.
Sequence 형태의 입력이 들어오면 출력으로 Sequence 형태의 출력을 반환하는 구조가 Seq2Seq이다. Seq2Seq는 크게 Encoder와 Decoder 구조로 이루어져 있다.
Encoder는 입력 Sequence를 입력받아 최종 출력으로 context vector를 반환한다. Decoder는 Encoder에서 출력된 context vector를 입력으로 받아 새로운 Sequence로 출력하는 방식으로 구조화 되어있다.
만약 Q&A 데이터셋을 이용하였다고 생각하고 예시를 들어보자. Encoder에 Sequence가 Q(질의) 문장 데이터라고 하자 그리고 Decoder의 Sequence는 A(응답) 데이터라고 하자.
Encoder에 질의 Sequence가 입력되면 마지막 RNN(LSTM) 셀의 은닉값을 Context Vector라고 할 수 있다.
이 Context Vector를 Decoder 첫번째 RNN 셀의 이전 Cell 은닉값으로 넘겨주고 Decoder 첫번째 입력으로
이후 Decoder의 첫번째 Cell은 Context Vector와
위 그림을 보면 오늘 날씨 어때 ? 의 Sequence가 Encoder에 입력되어 출력된 Context Vector가 Decoder의 첫번째 Cell에게 은닉값으로 전달되고
이 은닉값과 첫번째 Cell의 입력
이후 Decoder의 두 번째 Cell은 이전 Cell의 은닉값과 첫번째 Cell이 추론한 ‘날씨’ 라는 단어를 입력으로 받아 ‘매우’라는 단어를 추론하도록 학습한다.
위와 같은 과정을 거쳐 “날씨 매우 맑음” 이라는 Sequence가 순서대로 추론되고 ‘맑음’ 이라는 단어가 추론된 다음에는
Seq2Seq를 학습시키기 위해서는 Encoder input data(Question)와 Decoder input data(Answer)가 필요하고 Decoder가 올바른 방향으로 학습 될 수 있도록 Decoder의 입력이 들어가면 출력을 정답으로 알려주기 위해 Target Data가 필요하다.
Decoder input data는 “